
Full Text Search using Apache Lucene (Part-I)
Introduction:
Lucene is an open source, highly scalable text search-engine library available from the Apache Software Foundation. Lucene’s powerful APIs focus mainly on text indexing and searching. It can be used to build search capabilities for applications such as e-mail clients, mailing lists, Web searches, database search, etc. Web sites like Wikipedia, LinkedIn have been powered by Lucene.
Lucene has many features. It:
- Has powerful, accurate, and efficient search algorithms.
- Calculates a score for each document that matches a given query and returns the most relevant documents ranked by the scores.
- Supports many powerful query types, such as PhraseQuery, WildcardQuery, RangeQuery, FuzzyQuery, BooleanQuery, and more.
- Supports parsing of human-entered rich query expressions.
- Allows users to extend the searching behavior using custom sorting, filtering, and query expression parsing.
- Uses a file-based locking mechanism to prevent concurrent index modifications.
- Allows searching and indexing simultaneously.
Steps to build an Application using Apache Lucene:
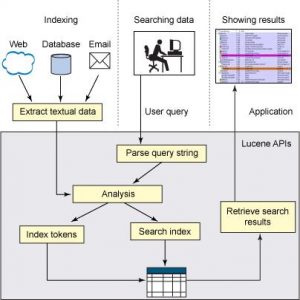
The below image demonstrates various stages/phases in building an application using Lucene.
- Indexing data
- Analysing data
- Searching Indexed data.
I will discuss about how to Index data to make it searchable and how to search Lucene indexed data in subsequent posts.
